
developed by BIO-IT Lab.
Dankook University, Korea

|
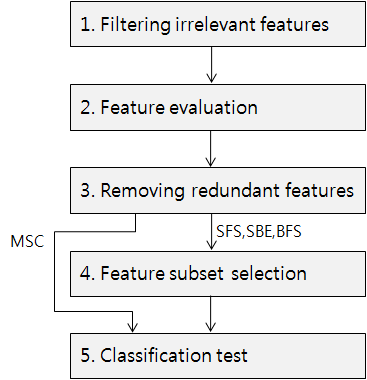
AmRMR
|
|
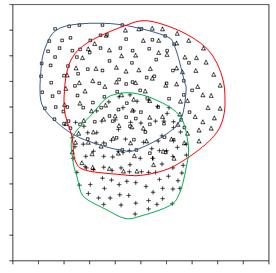
R-value
|
|
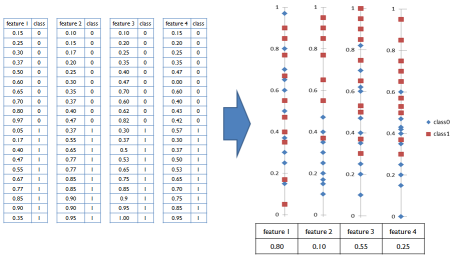
RFS
|

|
Concave Hull
|

|
UniPrimer
|
|
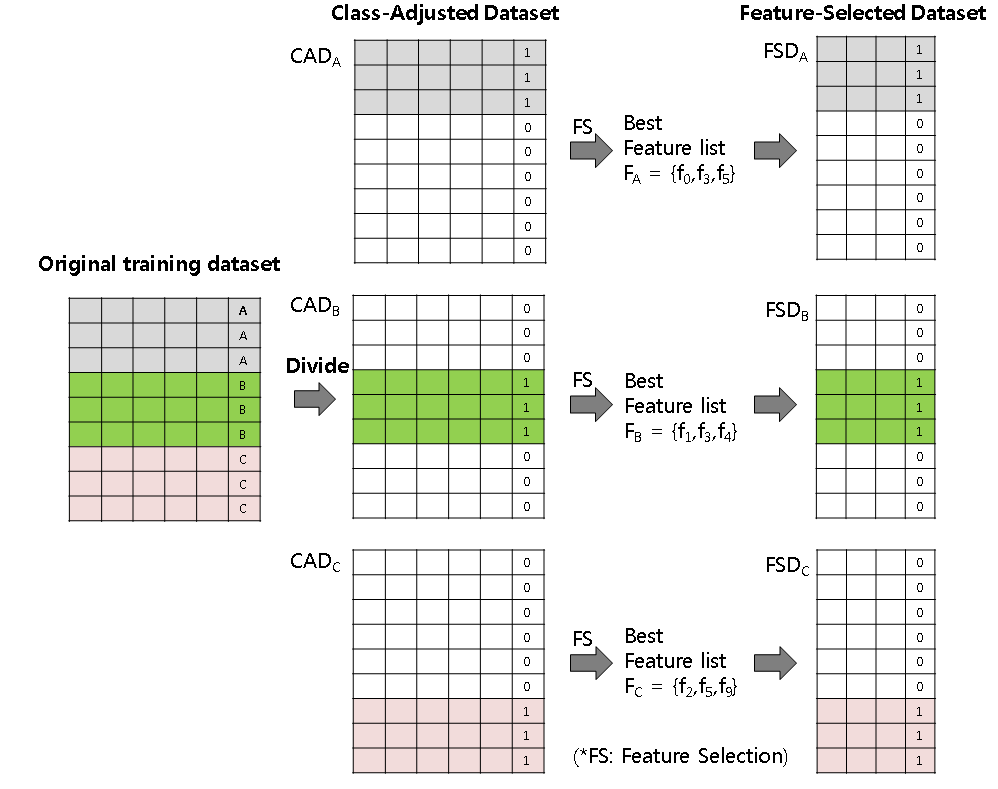
DAMC-MC
|

|
|

|
CBFS
|
|
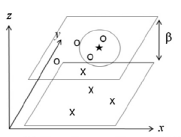
AGM
|

|
boostMDR
|
|
|
|
|
|
|
|
Find Biomarker
|